Keeping the BitBabbler hardware minimal, auditable, and verifiable
was the easy part of this project. The TRNG itself is constructed
entirely from ordinary off the shelf passive and analogue components,
which satisfies our provably nothing up its sleeves
requirement.
The only relatively complex part is providing a USB interface for easy
communication with the host computer. For that we selected the FTDI
FT232H, which is a well known and widely used dedicated USB interface
chip, with no general purpose CPU or programmable logic. It provides a
direct interconnect from the output stream of the entropy source to the
host, which means that it is not possible for an attacker to simply
reprogram the device in any way which could subvert the stream. They
would have to actually hijack its fabrication in some way that no other
user of this very common chip would notice – which severely limits
who might be able to mount such an attack. But even if someone was able
to do that, our design means it could still be detected. Since the
stream into that chip is expected to be exactly the same as what is seen
at the host, any moderately equipped person could always verify that for
themselves directly with a basic (or even improvised) logic analyser.
Any attack that is very expensive to mount, but very cheap and easy to
detect, puts the advantage firmly back into the hands of the defender.
The design that has tested the best for the TRNG entropy source is centered on using an analogue shift register to gradually and continually lift all available noise from the small signal levels where it naturally and relentlessly occurs, and where it is the most susceptible to being drowned out by other interference 'signals', to a 3.3V binary logic level where it is beyond any subtle environmental interference. An interference signal of that level would be almost certain to cause the rest of the computer system to malfunction in obvious and catastrophic ways. By incrementally amplifying and integrating the random noise that is present at each sample step we are able to capture all of it, in whatever form and amplitude it exists, without letting any single source or sample of it ever dominate the outcome of the final logic bit that is output.
The conventional distinction between analogue and digital circuits is a fairly clear cut one, analogue circuits are continuous in both signal range and time, while digital circuits are clocked (either explicitly or implicitly) with strictly discrete signal logic levels and intervals during which they are considered to be valid. But these are just the conceptual asymptotes at either end of reality. In any real physical circuit, its actual operation always lies somewhere between those two extremes. The transition between digital logic states on the wire is still fundamentally analogue in nature – and while an analogue signal may be considered continuous in time, its signal levels are still ultimately discrete, being some multiple of the smallest charge carrier which defines them, the electron. Conventional analogue circuit design just selects a signal level which is large enough that the influence of any single electron being randomly added to or subtracted from it is in the noise.
That noise however is very real, and both analogue and digital circuit designers generally put significant effort into making it as insignificant as possible. Our goal here was to do quite the opposite and distill it from any unwanted signal component, as pure, concentrated uncertainty. These fuzzy boundaries between the analogue and digital signal domains will be our apparatus for that.
There are a wide range of well studied phenomena which are responsible for the noise that occurs in electronic circuits:
Occurs in all circuits where a current flows, as a result of the charge carrying electrons being discrete quanta. The motion of electrons across a charge barrier is a Poisson process (as is radioactive decay) and each crossing is understood to be an independent and purely random event. The instantaneous charge flow constantly fluctuates around the mean in the continuous time equivalent of tossing coins (which is a Bernoulli process). Due to the small charge of an electron, shot noise tends to dominate when current flow is low, and becomes less significant as it increases (in the same way that many coin tosses will more closely approach the expected mean than a small number is likely to). Shot noise is independent of temperature and is spectrally white, occurring with uniform power density at all frequencies. This is an excellent source of noise for our design to capture.
Also known as thermal noise, this occurs as a result of the thermal agitation of charge carriers in a conductor. It differs from shot noise in that it is present even when no current is flowing, is independent of the amount of current flowing, and its intensity is temperature dependent. This source of noise is also spectrally white in the frequency range of interest to us (though it does deviate slightly from that at extremely high frequencies). Assuming you don't plan to use the device from inside of cryogenic storage, this too is a good source of uniformly random noise that we can tap into.
Also known as 1/f noise, it is attributed to a
variety of causes but is usually characterised as random
fluctuations of resistance in a (semi)conductor through which
current is flowing. The phenomenon occurs widely in the motion
of natural systems, not just electronic devices. This type of
noise is spectrally pink, with the power density being inversely
proportional to frequency. While its contribution to the overall
level of noise is diminished at higher sampling frequencies, in
conjunction with the other sources of noise available to us, it
is still a valuable source of randomness in this design.
This is similar to shot noise in some respects, except that it applies to the behaviour of charge carriers crossing a reverse biased semiconductor junction when its breakdown voltage is exceeded. It is a similar effect to Zener breakdown, though they occur due to physically distinct processes. The avalanche current which flows is very sensitive to both temperature and voltage changes, and the large voltage drop and current which can flow when breakdown occurs generates heat which can damage the junction if not well controlled. While this is a mechanism that is commonly used as a random source, since it can be simply constructed from cheap components, we haven't deliberately employed it here. The high level of environmental sensitivity, and degradation in performance outside of fairly narrow limits seemed like it would be more of a liability than a benefit to us in the current design. There may be some contribution from this effect in the amplifier circuitry, but it is likely to be relatively minimal.
Onomatopoetically known as popcorn noise, this typically occurs in semiconductors, at low frequencies but at relatively high levels (enough to sound like popcorn popping if listened to through a speaker). It is generally believed to be caused by imperfections in the semiconductor material, and is less common in modern devices, since they can be screened for it and now often get scrapped if they fail testing. As such it is unlikely to contribute in any meaningful way here.
This is not a constant source of noise like those described above, but parasitic capacitance in MOS switching transistors will result in excess charge being applied to their output when switched off. This phenomenon is present in our design, though its contribution to the total entropy is believed to be minimal.
The possible sources of this are many and varied, ranging from distant stars to just about everything on earth, and from purely random in nature to carefully crafted. Our current design does not try to shield itself from any of these (though it could quite easily be shielded by any user if they considered that desirable). Because each output bit is the result of lifting all noise of all magnitudes many times before it is realised for output as a logic one or zero, rather than simply sampling a single source for each output bit, even a strong interference signal should be well mixed with good non-deterministic randomness, and have minimal effect on the quality of the output. Short of simply frying the device with an EMP, or overloading it with a signal so powerful that it would likely cause the computer system itself to malfunction, it should be difficult to predict the effect that even a carefully crafted interference signal would have on the output. We do not deliberately try to tap into external noise (since a tuned antenna would be inviting targeted interference with it) but the broadband noise that all devices are naturally exposed to will be mixed in the same way as other noise is.
What we're aiming for then is a circuit which can take these relatively low levels of highly unpredictable noise and gently boost them until they drown out any predictable signal that may have entered the system. This is where the analogue shift register comes in.
An analogue sample and hold circuit, operating on a 3.3 volt supply rail, would normally be considered approximately to be able to hold any voltage between 0 and 3.3 volts. But if we take the details from above into consideration, we know that it can't really store any voltage. At any instant in time it can only hold a charge which is some multiple of the charge on a single electron. To change the voltage we need to add or remove electrons from it. Which means we can also model it approximately as a digital register holding a value equal to the number of electrons that it currently contains.
This lets us make some reasonable estimates of the number of possible states that the shift register may be in. In the current design, we can store about 11.5 billion electrons when it is fully charged. Which in digital terms equates to a register with about 33.4 bits of state, with the least significant bit being just one electron added or removed. Or put slightly differently, we can capture noise in the system down to about 286 picovolts (2.86 × 10-10).
If we were to try to amplify a signal from that level directly to what we need for a 3.3V logic output, we'd have a circuit that was very susceptible to being interfered with by a very small outside signal (ignoring for the moment that it would also be insanely unstable). So instead we make full use of the fact that we have the equivalent of a digital shift register and simply shift it one bit to the left, boosting a 286pV noise sample to 572pV. However since it's not purely digital, and since our relentless sources of noise don't go away while we're doing this, then rather than simply end up with 572pV, a new sample of the instantaneous noise level from all sources is also mixed in with that. Which leaves us with, well, we don't know exactly what, because that part is unpredictably random – which is exactly what we want.
Each time we clock the shift register, the previously accumulated noise is shifted one bit left, newly accumulated noise randomly flips some random number of the least significant bits, and the most significant bit is shifted out as the next bit of our random stream. As each bit moves toward the left, the probability of it being flipped yet again will decrease as it rises above the mean level of the available noise (as will its resistance to being interfered with in any deterministic way by a hostile external signal).
| Bit | 33 | 32 | 31 | 30 | 29 | 4 | 3 | 2 | 1 | 0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Voltage | 1.65V | 825mV | 413mV | 206mV | 103mV | 4.6nV | 2.3nV | 1.1nV | 572pV | 286pV | |
| 1.134V | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | |
| 2.269V | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | |
| 1.238V | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | |
| 2.475V | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | |
| 1.753V | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | |
| 0.206V | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
The table in figure 1 gives a rough example of how this works. The top rows show the approximate analogue voltages for each 'digital' bit of the shift register, and the subsequent rows step through a hypothetical sequence of clock cycles. The left column shows the approximate voltage of the register at each step, with the rest of the row showing which bits are set. A level of 3.3 volts would mean that all bits are set, with 0 volts corresponding to none set.
We assume for the sake of this example that the noise which we are capturing during this period is always smaller than 100mV, but exceeds 5nV most of the time. The bits between those levels are not shown to keep the size of the table manageable.
From these conditions we see that the high order bits on the left
side of the table behave as they would be expected to in a purely
digital domain. At each step they are simply shifted to the left, and
we take the most significant bit as our output. They are represented
by voltages which are above the normal noise floor, and will not be
randomly flipped unless an unusually high level noise spike occurs.
The output from this sequence would be the bits 010110.
On the right hand side of the table, the low order bits are all below the noise floor and there is no predictable pattern to them. At each step they are permuted by both the previous state and the current noise. If there were no noise, they would behave in the same way as the high order bits do, simply being shifted to the left at each step, but since bit 4 corresponds to a change of only 16 electrons (in a store of up to 11.5 billion of them), the probability of none of those bits changing randomly due to noise is extremely low.
In the transition zone between the high and low order bits, as they begin to be raised above the mean noise floor, the probability of being being randomly flipped by noise will decrease and digital domain behaviour will start to dominate. At some point along that line a random bit will emerge which will no longer change until it is finally shifted out of the MSB, as the unpredictable entropy we have captured.
So from this, we have a theoretically strong basis for efficient extraction of good entropy. We have sources of noise which are naturally white and for which the best scientific understanding is that the mechanisms underlying them are subatomic scale events which are as independently random as any kind of physical phenomenon is known to be. We have multiple sources of noise that are not all influenced by the same set of physical or environmental conditions. We have a mechanism to extract it which ensures good mixing over time and is robust against interference from predictable signals, over a wide range for the noise floor mean. We can implement it in a way which makes it obvious that no programmed manipulation of the process output is taking place. It is self stable and doesn't require continuous tuning to operate correctly. And we can clock bits out of it at just about any rate we please up to the effective bandwidth of the circuitry responsible for doing that. Our initial set of requirements are looking fairly well met.
Which means it's time to look more seriously at what sacrifices we must make to appease the exacting spirit of Reality.
Perhaps the first and most obvious thing that anyone practiced in the arts of practice will recognise, is that precision is finite. This means that not only can we not create a device which behaves in exactly the same way as its ideal model predicts, but if we create two devices, they will not behave identically to each other either. The good news is, if each device captures noise a little bit differently, and responds to external interferences differently too, that actually increases the expected robustness when using multiple devices together. The bad news is, math can do strange things when it isn't precise.
While the essential noise sources which we are capturing will not fundamentally change as a result of the component and manufacturing tolerances, what will change in quite interestingly chaotic ways is the precise mathematical function which is applied to them at each step as we elevate them above the noise floor.
For a start, the storage we have (~11.5 billion electrons) is not an exact power of 2, and even if we were to carefully select component values which were closer to one than this (which would in turn have other engineering tradeoffs), it would still be essentially impossible to create a physical device with tolerances so precise that we could achieve that exactly. Which means if we were to start with just a single electron in it, and double the number of them at each step with no additional noise component, we would not be able to completely fill our storage without some overflow or truncation at the final step. Similarly, if we were to start with our storage full, and shift bits out of it with no variation due to noise, somewhere along the line we will have an oddball number of electrons and some degree of quantisation error to our math.
In the same manner, we also cannot precisely double or halve the number of electrons at each step, we will over or undershoot that value each time by some continuously variable percentage. There are other limiting realities which also come into play and add extra complexity to our otherwise simple algorithm, which we can model the effects of, but which cannot be precisely measured on any given device, which cannot be easily determined by analysing its output, and which we cannot simply ignore.
While it is tempting to think that all of these unpredictable factors could only add pure awesome to a device built with the sole intention of creating unpredictable bits, it turns out that is not how either irony or reality actually works. These errors take our pure unpredictable noise, and start to make it predictable again …
One of the more curiously interesting effects that result from using an analogue system which effectively, if not actually fundamentally, introduces these sort of imprecisions and 'hidden variables' to what would otherwise be fairly simple and completely deterministic math, is the emergence of discrete (dare we say quantum) preferred states from imperfectly integrating and multiplying an initially uniform range of random impulses.
In both modelling and practice we find that this lack of perfect precision creates a distorted pattern of probability in both chaotic and predictable ways. The most predictable and easily understood effect is a constriction of the longest continuous sequence of zeros or ones before a bitflip must occur. But what we also see as the storage register bounces around between all of its possible states, permuted by just uniformly random impulses and basic math, is that it will tend to spend more of its time in some particular states than others. It doesn't actually get stuck in those states, nor does it get stuck in fixed cycles which simply return it to them repeatedly. There are just some states that it can approach from more prior states than others, so it ends up in them, or near them, an unequal proportion of the time. The natural and non-linear imperfections we have in the analogue implementation of the math that is permuting them leads to something which has at least a superficial resemblance to the distribution of prime numbers, or other similar functions. There are regions of the state space which become relatively void, and regions which are more dense than would be expected from a uniform distribution. Which of those distortions happens where in that space has varied chaotically from device to device in actual testing, and does so with very small changes to the operating parameters in modelling too.
[ This is not what the image below is actually showing, but it's similar enough on a different measurement to still give you some visual sense of this ]
While this was food for a whole lot of other interesting thought, it actually posed a very real problem that we needed to address. Our lovely white noise was no longer white. We could model the system without these imperfections and get the perfect results we were hoping for, but it was going to be impossible to ever build such a device in the real world that we have to work in. We needed to prove that the error was not cyclic and did not introduce a deterministic or otherwise predictable pattern to the output stream beyond the distorted probabilities, and we needed a way to make it white again if and only if the stream of bits that we did have truly were still independently, if no longer so uniformly, random.
We'd already established in our initial requirements that needing to do cryptographic whitening was a showstopper. Not because there is anything inherently wrong with that if you are already as certain as you ever possibly can be that your entropy genuinely is random, but simply because it can completely hide the fact that your entropy most certainly is not. As much as we had some tentative faith in the theoretical grounding of this design, that wasn't worth dirt if we couldn't prove it through proper testing or if a real implementation of it had some actually observable weakness that could be exploited. We needed something a lot more primitive, that could smooth out the quantisation resulting from the imperfect math, without hiding the real underlying nature of the entropy we were collecting.
If the bits in the stream are uncorrelated, then we can segment the stream into multiple parts as if they were individual streams from separate sources. In RFC 4086 it is explained how such streams can be mixed together, and how if they are both uncorrelated and random, the 'eccentricity' of them will be reduced. AIS-31 §5.4.2 further explains how for non-overlapping segments of independent bits:
… with independent, identically-distributed biased binary-valued random variables … The xor-sum of the bits smoothes exponentially the bias of the independent bits. These sums are independent, as well.
Which seems like just what we're looking for, a mathematically transparent operation which will bring back the whiteness if the stream is good and may help to highlight any correlation if it is not. It is definitely not the most efficient known method for extracting uniformly distributed bits, but with a high rate of bits available from the device that is not a major problem here. The important property for us is that it should be terrible at masking any genuine weakness in the stream while improving a good stream enough to directly subject it to more rigorous statistical testing. It's not entirely foolproof at that, but it's not going to completely launder away problems which we do want to discover like a strong cryptographic hash or a CRC function would.
In the particular case of this design, there is also another benefit to us 'folding' the stream in this way. As we noted above, the Flicker Noise spectrum is pink, and so its power diminishes as the frequency increases. By folding the stream in suitably long segments, we can increase the contribution of low frequency noise to each output sample while still clocking bits out at the highest effective rate.
In the final design that we've so far settled on, folding the stream twice is enough to make it very close to perfectly white again. Whether that was more than enough, or not quite enough, to pass even the most rigorous statistical verification on very long streams of bits, varied from device to device and with the speed we clocked bits out of them, due to small differences in component tolerances. After more rounds of experimenting, some changes to the component selection and some further modifications to the PCB design, we improved that a bit more again. Since folding it twice is equivalent to mixing the output of four devices together, we then also built a device with four generators on the same board, that can be individually selected for testing, or run all together to achieve the same result as the folding, but at four times the output bitrate.
After an intensive period of testing on the first hundred devices we have fabricated, we've settled on a set of 'safe' defaults which we think should give good results for all devices, taking into account the expected (and observed) component and production tolerances and a wide range of operating environments. Unless configured otherwise, the software will default to clocking bits out at a rate of 2.5 Mbps, folding the output of a quad TRNG once, and of the single generators three times. We have individual devices that we've been able to clock reliably at 5 Mbps (and all devices can be clocked even faster than that, up to 30 Mbps, but the whiteness of the raw stream will degrade as the speed is increased too far), and we have quad devices which produce excellent quality output without any folding at all – but we've elected to use conservative defaults because for most users that will still provide fresh entropy much faster than they are likely to be consuming it in normal use, and we'd like those people to be able to just plug it in and use it immediately, without needing to experiment for a set of optimum parameters. For people who do want to do that though, both the bitrate and level of folding are software selectable.
Us throwing every test we can think of at this to prove the practice lives up to the theory is one thing, but the really important part is that it continues to pass sanity testing while it's actually in use on a live system. All the prior proof in the world isn't worth anything if a device has malfunctioned on site, for whatever reason, and is happily flooding your entropy pool with bad bits.
To that end we've provided, by far, the most comprehensive suite of real-time quality tests, which every sample is subjected to before being mixed into the entropy pool it is supplying. Long term and short term performance metrics can be queried on demand, and graphed in detail with the help of munin.
Traditionally (and at the recommendation of various national standards bodies), continuous testing has generally consisted of only a few very basic sanity checks, which are mostly only able to catch a complete, or near complete failure of the entropy source. This may have been a reasonable suggestion in an era when these tests were assumed to be running on some wind-up toy calculator with barely enough resources to do some simple math, but that's not the reality of most machines that are in need of good entropy today. While it still may not be practical to continuously run a heavy torture test suite like Dieharder, or all of the tests in the NIST 800-22 suite, it also seems almost criminally negligent to rely on nothing stronger than the tests that were originally described in FIPS 140-2 (which in fact removed the requirement to run continuous statistical tests in its latest revisions anyway).
The FIPS 140-2 tests have the advantage of operating on very small blocks, which means they can very quickly detect a catastrophic loss of entropy before it pollutes the pool. However they also have the disadvantage of operating on very small blocks which means they will still pass things with the potential to be exploitably not random. At the very least they will pass things which other tests will very quickly flag as observably not random. They were also calibrated to a significance level which means that they are expected to fail on about one in every 1250 blocks on average of a genuinely uniform random stream (about every 3MB) – which means if blocks that fail those tests are naively filtered out, then an otherwise good stream will also be rendered statistically not-random, and would be prone to failing more thorough tests for good randomness. This complicates the benefit of them being able to detect an anomaly quickly, since you then need a separate test to determine if they have failed an actually statistically significant number of times more often than they are expected to … (which few things actually do, and which that standard offers no guidance about).
The good news is, it turns out that a large number of the tests which
we had been using for our initial long-term assessment of these devices
are also quite cheap to run. So there's almost no excuse not to just run
them all of the time, use them as part of the continuous health and
quality checking, and provide
RRD graphs of those results
for monitoring. Right now we include: The FIPS 140-2 tests, which were
verified against the independent implementation in the rng-tools
package (in which we then found and submitted patches for a
couple of bugs), and for
which we verify not only the expected failure rate, but the expected run
length without any failure too (which would also indicate the stream was
not statistically random). The Adaptive Proportion Test and min-entropy
estimation from the NIST SP 800-90B 2012 draft (for which there is no
final release yet at this time). The metrics from John "Random" Walker's
ENT suite, which we
implemented for both 8 and 16-bit samples. A measure of the expected vs.
actual number of runs of consecutive zeros and ones, which turns out to
be very similar to the "General Runs Test" described in AIS-31. We track
both short-term results (either as independent tests on suitably small
blocks or as a rolling average depending on the test) and long-term
results (over all samples seen since the monitoring process began),
which gives a good balance between quickly detecting some sudden
failure, and not missing some anomaly which only becomes evident after
analysing a very large number of samples (some tests become increasingly
sensitive to smaller abnormalities as the sample size grows).
We still have a number of other tests in mind that may be interesting to add to this set in the future, and a few that we have experimented with for general analysis but which are either tricky to provide a simple go/no-go significance test that can be automated, or which are just too computationally expensive to run continuously on a machine that is supposed to be doing other real work. So far though, every device which has been successfully passing all of the above tests has also been passing runs through Dieharder, the NIST suite, and TestU01, so there's probably still a few other things that we can more usefully improve or flesh out first before we come back to that again.
If there's some test you think we've missed that would be particularly valuable to add to this set, we'd love to hear more about that too. We're serious about this being a very important part of doing this job properly.
So we think we have a good design. We think we have a good implementation of it. We think we have a good set of tests to verify this. But none of that is much help if we don't also have a good way to use it!
For general purpose testing of your own, or for applications where
you simply want a stream of random bits directly out of the RNG hardware,
this is easy, you can just pipe the output (of any number of devices if
you have more than one) to stdout and use it however you
please.
The use case which we originally needed though, and which many people will probably also get the most value from, is to use it to feed the normal system entropy pool. On Linux at least, this is a relatively straightforward thing to do as well, and our software contains everything needed to support that. If you have only one device in the host system, then mostly you just plug it in and you're done. If you have more than one device though, then you also have a few more options available for configuring exactly how you want that to work, which we'll talk about in more detail below.
For BSD, it depends a bit on which variant you are using, since there are some differences between them as to how system entropy is handled.
For Windows, you're probably best off avoiding their system CryptoAPI altogether, since while it does ostensibly provide a way to feed seed entropy to the PRNG it uses, there is no way to know if or how it will actually use what you feed it with. Applications which need some guarantee about the quality of the entropy they obtain can read directly from the UDP socket interface we provide for that.
The UDP socket interface is available for all platforms and permits requesting packets of entropy directly from the BitBabbler output pool. It can be enabled in conjunction with any of the other output methods above.
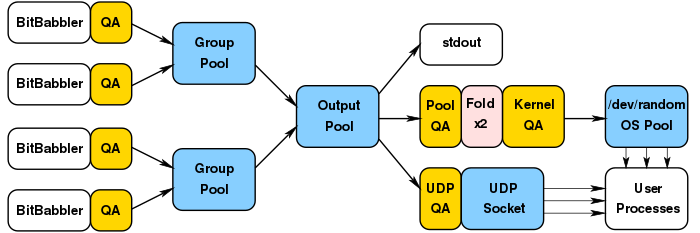
The diagram in figure 2 shows the general flow of entropy through the system. Any number of BitBabbler devices may be employed. Each device can be grouped together with up to 32 other devices, and devices can be allocated among as many separate groups as you wish to have.
The default configuration is for each device to be in its own separate group. Entropy is read from each device, subjected to QA checking, and then (if it passes) mixed into the group pool.
When more than one device belongs to an individual group, entropy from that group pool will not be mixed into the output pool until every device in that group has made a good contribution to it. This is a more paranoid configuration than the default and ensures entropy from multiple devices will always be mixed together before it can be used. It does however mean that failure of any single device in that group will prevent all of them from contributing further entropy to the output pool until the offending device is removed or the problem with it is resolved. It also means that entropy will only be supplied by that group at the rate of the slowest device which belongs to it (though any faster devices will continue to mix more entropy into the group pool during that time).
Having devices in separate groups provides a simpler form of redundancy, so that if one group fails, the others will continue supplying the output pool. Using separate groups also means that under the highest demand for entropy, the maximum rate will be equal to the sum of the output rates of all available devices. Both options can be combined on the same system, and multiple groups of multiple devices can be used to achieve exactly the right balance of paranoia, redundancy, and available bitrate that your situation requires.
When every device in a group has provided at least as much good entropy as the size of the group pool, that group pool will be emptied into the output pool, mixing with any entropy already in it (either from other groups, or because it was not consumed since the last time that the group pool was filled).
Entropy from the output pool is supplied on demand, either to a process reading from it directly (via a stdio stream or the UDP socket interface) or to the operating system's pool. The OS pool is topped up from the output pool when its entropy content falls below the configured watermark, and at periodic intervals when it does not.
When supplying entropy to the OS pool, a block of 20,000 bits is read from the output pool and subjected again to QA testing. This means that at minimum a full block will be analysed using the FIPS 140-2 tests. If it passes that (and all the other QA tests, some of which operate over much larger blocks of samples), it is then folded twice, into a block of 5000 bits. That block is again subjected to QA testing, and only if it also passes that will it be supplied to the OS pool. On Linux, unless the OS pool size was manually reconfigured, it will credit us for at most 4096 bits of entropy (if its pool was absolutely empty at the time) – which means we take 20k bits, which should have very near to 8 bits of entropy per byte, mix that down into 5k bits which we provide to the OS pool, and credit them for adding at most 4096 bits of new entropy to it. We have a high volume of bits available, so we can afford to be conservative about the amount of entropy we are claiming for them.
The QA checks can be bypassed when streaming to stdout
(in which case they are still run for reporting purposes, but will not
prevent bad blocks from being output), to facilitate proper analysis by
external tools (like Dieharder or TestU01), since it would be a fairly
pointless rigged demo if we were to hide any of the stream from them.
There is no configuration option to allow disabling them when feeding
the OS pool though, since there should be no good reason to ever do that
intentionally.
We gave quite a bit of thought to the question of how to best handle physical security of the device. A number of the national standards documents make recommendations or have requirements for varying degrees of tamper-evidence or protection, and a number of methods of attempting such things are widely used. Unfortunately, the problem with pretty much all of them is that they either make it difficult or impossible for the legitimate user of the device to ascertain that it was not already tampered with before it came into their possession. Or they add extra layers of complication to the design which include programmable elements that may in turn be used to subvert the device. Or they are simply little more than something which got a few chuckles on open mic. night at security theatre. And sometimes, they do all of those things.
Complicating this even further is the fact that there really is no simple one size fits all answer that can meet the needs of every situation. If you only ever plan to use this in a laptop, and will carry it securely on your person at all times, what will work best for you is different to if you want to use it in a commercially hosted rack, in a data center that you'll never, ever visit personally – which likewise will be different to if your machines are located on a remote island, surrounded by shark and crocodile infested water, in a high-walled compound full of hungry lions, with a hermetically sealed server room filled with nerve-gas and surrounded by motion sensitive laser cannons, that shoot everything which doesn't move too, just to be sure. And so on, and so on. The only thing that really was quite crystal clear is that under no circumstances should we do anything that would limit your ability to inspect the device in detail and verify its integrity to your own satisfaction, at any time you please, and we especially shouldn't do it in exchange for just xkcd 538 security.
Which ultimately meant, the best thing to do was looking a lot like nothing at all. Or at least nothing that we hadn't already done. We could seal it in epoxy which would destroy it if opened – but so could someone who intercepted it in transit and substituted a compromised clone. We could put a magic number in it and do some hand-waving about cryptographic signatures – but without a strong chain of trust (or even with one for the most part) that just gives the same attacker a general purpose CPU to make their job even easier. We could pad the 'unused' parts of that processor's ROM with 'random bytes' and pretend that isn't a giant side-channel waiting to be packed to the brim with delicious … oh, wait. We could … well, yeah, we could probably safely stop right there, and try to think about this part a bit differently.
We could go back, right back, to the very basics. We could go back to the one word which underpinned every decision that we made along the way. We could put our faith in trust. Not trust in us, or in a just society, or popular fads, or in any mechanism we might contrive or have read about on the internet. Trust in the individual ingenuity of each user to come up with some personal set of assurances that works right for them. There are lots of things which are easy to do. You could encase it in epoxy, after you've put it to every test that us letting you open it up enables you to do. You could fill that epoxy with glitter, and take high resolution photographs of the unique 'fingerprint' that creates. More simply you could just paint it with sparkly nail polish if you want to keep your options open to be able to open and test it again later. You could put it under constant video surveillance. You could encase it in a Faraday cage and electrify that with a million volts (but when you get arrested for setting a man trap, we'd be very grateful if you didn't mention us, thanks). Or you could quite simply just not care about any of this at all, if for your particular use case and situation, none of this factors into your own threat model. Maybe you already have a large dog. Maybe you're a statistician and don't want this for security related purposes at all, outside of maybe job security.
The best form of physical security is something which isn't well publicised, which any adversary doesn't even know they need to avoid being outsmarted by, which they can't train or practice to become adept at dealing with, which they won't know has alerted you to the fact that they've paid you a visit. So we came to the conclusion that probably the best thing we could do is just not do anything that gets in the way of your freedom to do whatever you think is best. And that it would probably be best if we also didn't talk too much about the huge variety of options you have for this, and spoil the fun of them remaining a personal secret. You need more than obscurity to ensure that it can help with your security needs, but entropy isn't the only thing which is better while it still remains unguessable.
With all that said though, we are still interested in any genuinely useful things that we could do which would improve this side of things without also compromising on the other important requirements. It may well be the case that there is enough common interest to specialise some subset of devices for particular uses, or that there are more generically good things which we could do that would help everyone, or at the very least, harm no one.
This is the point where feedback from other real users takes over from trying to think too hard in advance and make guesses about what they might really need, based on just what we needed ourselves (or what some random people on the internet say they think). Not all of that advice is bad, but not all of it is relevant to every user either, so the best thing we can do is listen to people who share our interest in getting this right.